
Attention in RecSys: When Attention Stops Paying for Itself
Part 1 of a series on scaling user sequence modeling in production RecSys. Don’t want to read a wall of text? Here’s the audio/video explainer, thanks to NotebookLM.
Self-attention is the cornerstone of Large Language Models (LLMs). It’s what allows Claude, GPT, and Gemini to understand the syntax, resolve ambiguity, and generate coherent text across thousands of tokens. But in RecSys, self-attention plays by entirely different rules. Having worked on scaling attention-based RecSys in production, I’ve come to appreciate how these differences fundamentally change the resource investment strategy: when self-attention is worth its computational cost, and when it isn’t.
Why Self-Attention Is Non-Negotiable for Language
Human language is governed by strict rules of grammar and syntax, which is why self-attention is non-negotiable for LLMs.
- Order and Syntax: Word order fundamentally changes meaning. “The cat chased the dog” is entirely different from “The dog chased the cat.“
- Contextual Ambiguity: A word’s meaning is derived from its relationship with other words. For example, self-attention allows a model to understand that “bank” in “river bank” is different from “money bank” by weighing the influence of surrounding words like “river” or “money.”
- Long-distance dependency: a pronoun at position 500 must link to a name at position 12.
Self-attention solves these problems by computing pairwise relationships between every token in a sequence, an O(n²) operation that is computationally expensive but linguistically necessary. Without it, a language model cannot parse grammar, resolve ambiguity, or maintain coherence across long passages. The cost is the price of understanding language.
What Self-Attention Does in Recommender Systems
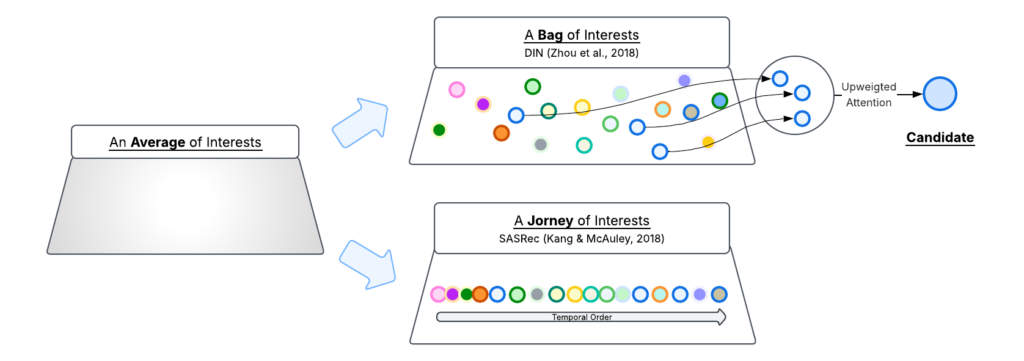
To appreciate what self-attention unlocked for RecSys, we need to understand what came before it. Historically, RecSys models treated a user’s interaction history as an average of interests: pooling operations (sum, mean, or weighted) collapsed thousands of past interactions into a single static embedding. This representation had two fundamental blind spots:
- No selective attention. A user’s interests are diverse – cooking, fitness, travel – but the pooled embedding blends them into one indistinguishable vector. When ranking a ski jacket, the model has no way to amplify winter sports signals and suppress cooking signals. Every candidate faces the same blurred snapshot.
- No temporal ordering. A user who was obsessed with cooking six months ago and recently shifted to fitness looks identical to one with the reverse trajectory. The evolution of interests, what’s rising, what’s fading, is lost.
Two breakthroughs in 2018 addressed these shortcomings from different angles.
- From an average to a bag of interests. DIN (Zhou et al., 2018) introduced target-aware attention: the candidate item acts as a query against the user’s history, activating relevant interactions while suppressing irrelevant ones. If the candidate is a ski jacket, the model amplifies past winter sports clicks and ignores cooking videos. Interests now have resolution: the model can distinguish and selectively attend to individual affinities rather than facing one blurred average.
- From a static snapshot to a temporal journey. SASRec (Kang & McAuley, 2018) introduced self-attention over user interaction history (UIH), processing it as an ordered sequence where each interaction attends to each other. For the first time, the model could capture the trajectory of interests — how they shift, intensify, and fade over time.
Unifying resolution and trajectory
Each breakthrough left something on the table:
- DIN gave the model resolution, and enabled candidate-specific attention over UIH, but it treated UIH as an unordered set, with no temporal trajectory.
- SASRec gave the model trajectory, and can detect temporal dynamics of evolving interests, but the candidate item only appears at the very end as a passive dot-product against a fixed user embedding. The user representation is the same regardless of which candidate is being scored.
Subsequent architectures, most notably HSTU (Zhai et al., 2024), unified both by placing candidates inside the attention computation. Rather than treating UIH encoding and candidate scoring as separate stages, HSTU concatenates the candidate items with the UIH to form one combined sequence. The rationale, as stated in the paper, is that “interaction of target and historical features needs to occur as early as possible“, so as to enable the model to learn which parts of a user’s history are most relevant to each specific candidate across every layer, producing richer, target-conditioned user representations.
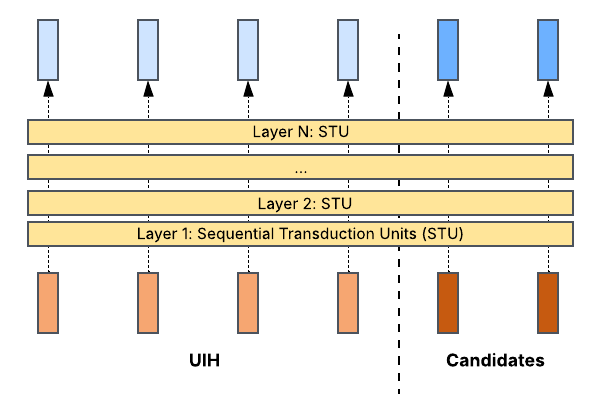
This unification raises an obvious engineering question: how do you make this computationally viable when there are hundreds or thousands of candidates? The key insight is that attention is inherently parallel: all candidates can be processed in a single forward pass rather than one-at-a-time in a sequential loop. The M-FALCON framework in HSTU packs the UIH and all candidates into one sequence and modifies the attention mask so that “the attention operations performed for bm candidates are exactly the same“: using a causal mask, each candidate attends to the shared UIH tokens but not to other candidates. This reduces the cost significantly and leads to the result: a 285x more complex target-aware model deployed at 1.5-3x the throughput of the simpler model it replaced. This design is subsequently echoed by the Request Level Batching (RLB) design from Tiktok’s Make It Long, Keep It Fast (Guan, L. et al. (2025).
What does this mean for the user? Consider a user who watched NFL highlights heavily during football season three months ago.
- Reviving dormant interests. When an NFL video appears as a candidate, target-aware attention amplifies those older football interactions: the model “remembers” a seasonal interest that pooling would have diluted into the average.
- Candidate-specific resolution. When a cooking video appears instead, a completely different subset of history lights up. Each candidate sees a different user.
- Detecting emerging momentum. If this user has been watching more fitness content over the past week, self-attention captures the temporal trajectory and recognizes an emerging interest, even before it dominates the history.
This combination: candidate-specific resolution plus temporal awareness, is what makes attention in RecSys fundamentally more than just a better encoder.
The ROI Tradeoff: When Self-Attention Stops Paying for Itself
The cost challenge
By default, self-attention computes pairwise relationships between every element in a sequence, creating O(n²) complexity. At 1K UIH, that’s 1 million computations. At 16K, 256 million. At 200K, 40 billion. On the other hand, the marginal value of additional UIH follows a log-linear curve: each doubling adds a roughly fixed increment of quality, not a fixed percentage. The first 1,000 interactions reveal core interests; the next 1,000 add meaningfully less.
Quadratic cost scaling up, logarithmic gains scaling down: these two forces inevitably create a break-even point. Extending UIH from 1K to 4K yields strong ROI. From 4K to 16K, the tradeoff shifts. At 100K+, full self-attention is non-viable at production scale. So how to solve this?
Different rules, different solutions
The way out is to exploit a fundamental difference: self-attention in LLMs and RecSys follows different rules.
- In LLMs, self-attention resolves compositional dependencies: grammar, syntax, and long-distance dependency: a pronoun at position 500 must link to a name at position 12. Every token can be critical to every other token, regardless of distance. The attention pattern is dense by necessity.
- In RecSys, self-attention captures evolving user interests over time. The signal structure is fundamentally different: it follows a recency-based value curve where recent interactions carry high-fidelity sequential signals (intent shifts, saturation, momentum), while older interactions contribute primarily through their aggregate patterns rather than their precise ordering.
These differences in signal structure mean RecSys can make architectural choices that would be unacceptable in NLP.
Matching attention granularity to signal value
This analysis points to a design principle: match your attention granularity to the signal value at each time horizon. Three intuitions guide this in practice.
Intuition 1: The gist matters more than the order. For a user’s distant history, the collective signal of a block of interactions: “this user was into cooking that week” is far more predictive than the exact order of videos within that block. This suggests we can compress older UIH by folding N adjacent interactions into a single summary token, capturing the content of that period while drastically reducing sequence length. ByteDance’s LONGER (Chai et al., 2025) applies token-merging to scale end-to-end modeling to 10K+ items with ~50% FLOPs reduction and near-lossless performance. Note that this compression should be applied selectively: recent UIH still needs full token-level resolution to detect momentum, saturation, and intent shifts.
Intuition 2: Global interests outweigh local ordering, so trim accordingly. If RecSys signal follows a recency-based value curve, which parts of the history actually matter when attending over long sequences? Inspired by DeepSeek’s Native Sparse Attention, ULTRA-HSTU (Ding et al., 2026) tested this directly by restricting each token’s attention to two sparse windows: a local window (K₁ nearest neighbors) and a global window (K₂ oldest interactions). The finding is striking: global-only attention loses just 0.03% quality, while local-only loses 0.35%, a 10x gap. In other words, a user’s long-term baseline interests matter far more than the precise ordering of adjacent interactions. This means we can aggressively trim local attention, reducing complexity from O(n²) to O(n), with minimal quality loss.
Intuition 3: Recent history deserves deeper computation. As we stack more attention layers, do all of them need to process the full sequence? ULTRA-HSTU (Ding et al., 2026) found that they don’t: “motivated by the importance of users’ most recent interaction history,” they stack N₁ layers on the full sequence to capture long-term context, then N₂ layers on only the most recent segment to concentrate deeper computation where it matters most. The result: significantly better quality-cost tradeoff than processing the full sequence at every depth. This layer-level separation also opens up significant optimization opportunities – including inference caching of the stable long-term layers – that we’ll explore in Part 2.
What’s next
From the M-FALCON framework that makes target-aware attention viable, to the compression, sparse attention, and layer truncation techniques that reduce its cost, these are optimizations within the self-attention paradigm. To truly scale to 100K+ lifetime user histories, we need to rethink the architecture itself: decoupling inference cost from sequence length entirely. In Part 2, I’ll explore the structural approaches that make lifetime UIH of 100K+ possible.
Stay tuned for Part 2: Scaling to Lifetime User Histories.
References
- Zhou, G. et al. (2018). Deep Interest Network for Click-Through Rate Prediction. KDD 2018.
- Kang, W. & McAuley, J. (2018). Self-Attentive Sequential Recommendation. ICDM 2018.
- Zhai, J. et al. (2024). Actions Speak Louder than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations. ICML 2024.
- Guan, L. et al. (2025). Make It Long, Keep It Fast: End-to-End 10k-Sequence Modeling at Billion Scale on Douyin. arXiv preprint.
- Pi, Q. et al. (2020). Search-based User Interest Modeling with Lifelong Sequential Behavior Data for Click-Through Rate Prediction. CIKM 2020.
- Yuan, Q. et al. (2025). Vista: Generalized User Modeling via Cross-Surface Transfer for Enhanced Recommendation. ICLR 2026.
- Aixin, L. et al. (2025). Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention.
- Ding, Q. et al. (2026). Bending the Scaling Law Curve in Large-Scale Recommendation Systems.
- Chai, Z. et al. (2025). LONGER: Scaling Up Long Sequence Modeling in Industrial Recommenders

Our Subdomain Service Now Offers Fully-Featured Webspace with PHP, MySQL, FTP, Cronjobs, Email…
RS_c Starts a Free Subdomain Service: https://Your-Project.Recommender-Systems.com

Netflix creates personalized “Sizzles” (video previews)
About The Author
Maggie Zhuang
Maggie Zhuang is an AI Research Product Manager at Meta, specializing in the ranking architecture of large-scale recommender systems, with a focus on sequence learning and semantic representation in ranking models. Previously, she built extensive experience in internet-scale data platforms. She writes about the strategic and technical trade-offs of complex AI systems at magicmag.ai.