
Academic Writing
This page provides guidelines on academic writing for Bachelor’s, Master’s, and Ph.D. students in the field of recommender systems, and related disciplines.
Table of Contents
Structure of a paper or thesis
When writing a paper or a thesis, we recommend the following structure.
Title
A good title is catchy yet descriptive, and it makes clear that you have created something awesome. Unfortunately, the standard title many students choose is “Doing X Using Y“. For instance:
- Detecting Cancer in Images Using Machine Learning
- Using kNN for News Recommendations
That’s boring. Besides, just applying or “using” some out-of-the-box machine learning algorithm to solve a well-known problem, is not very original. Even if you did just apply an out-of-the-box algorithm on a known problem — which may be absolutely fine for a Bachelor’s or Master’s thesis — there is no reason to point your readers to it directly in the title.
Therefore, consider the following:
- Give your algorithm or method a name
- Avoid the term “using”
- Make the title special
For instance, instead of writing “Using kNN for News Recommendations”, write “kNNews: A novel Technique for News Recommendations” (this is still not a ground-breaking title, but certainly better than the first one).
Abstract
A good abstract summarises the most important things from each section (background, research problem, methodology, results, …), typically in one or two sentences. So, in total you have one paragraph with a handful or dozens of sentences.
When writing an abstract, do the following
- Be specific: Provide numbers, in particular, summarise the most important numbers from your results.
- Bad: “We compared method A and B and present the results in our paper” (without saying which method was better, and what the actual results are)
- Mediocre: “We compared method A and B and found that A is more effective than B”
- Best: “We compared method A and B in an online evaluation with 8 million recommendations delivered to 300 thousand users. We found that A is 35% more effective than B with a precision of 0.76 vs. 0.56 (p<0.01)”
- Focus on your results. Many people write ten sentences about, e.g. how important recommender systems are, and then one sentence about their main finding. It should be the opposite. Potential readers most likely know already what, e.g. a recommender system is. So, don’t waste too many words on providing background information in the abstract. Describe as many results and findings as possible.
- Write a lot: The abstract is the text that is publicly available and that is indexed by search engines etc. So, write a decent number of words. In particular, if there is no page limit, writing a few hundred words is fine (if you have enough relevant information to put in).
Most people don’t put much effort into writing abstracts – that is a mistake! The abstract is the text that makes a reader decide whether to read your paper or not. Many readers might even only read your abstract to decide whether to cite your paper or what information to cite. I claim that with a good abstract you can double or triple the probability that someone reads and/or cites your paper. So, think about it: You have spent weeks or months doing your research and writing the paper. Hence, you should spend more than 2 minutes writing your abstract.
A very nice example of a good abstract is this:

The abstract has around 1 sentence for each important part, i.e. each key chapter in the paper (introduction/background; problem; goal; methodology; results) and the benefit is very clear (found the wreckage within 1 week, while others were unsuccessful for 2 years).
Introduction
The introduction provides background information, outlines the research problem, and states the research question and goal. In a normal 8-page research paper, the introduction is around 1 page. In a long document such as a dissertation, you may have separate sections.
Background
Every academic document starts with a brief (!) background that helps your readers to understand the context of your work. In a research paper, it might be just one or two sentences. In a Bachelor’s or Master’s thesis, it might be one or a few paragraphs. In a Phd thesis, one or two pages.
The background section helps to “set the scene” and must be related to your exact research topic. As a rule of thumb, ask yourself, is your background section unique, or could you copy it to almost any paper or thesis relating to, e.g. machine learning or recommender systems? If your background section is so generic that it’s suitable for any paper, then it’s not good. Your background section should be unique to your project.
For instance, suppose you want to analyse how important Hyper Parameter Tuning is, particularly whether Grid search or random search is better. Then your background could read like this:
Hyperparameter tuning is highly important to achieve optimal performance of machine learning algorithms. Research shows that optimized models perform up to XYZ better than not-optimized models (Reference). Two of the most commonly used methods to optimize hyper parameters are grid search and random search.
The background section in your introduction is not intended to explain what, e.g. recommender systems or machine learning are. That would be far too broad, and you could just refer the reader to a Wikipedia page. Here is a really bad example:
The world has witnessed a swift advancement in technology over the last 200 years. Following the invention of computers in the 20th century, the initial recommender systems were developed during the 1990s. Since that time, recommender systems have become widespread across nearly all online services. Whether in e-commerce, music, or movies, recommender systems are ubiquitous. These systems generally utilize either content-based filtering or collaborative filtering. Their performance is typically measured using precision, nDCG, or RMSE.
The problem with the background above is that it is so generic that it could be placed in almost any paper about recommender systems.
Research Problem
Formulating an important research problem is absolutely crucial. You must convince the reader that your work is solving an important problem. If the problem that you are solving is not important, then your solution to the problem can’t be important. However, many readers of your papers may not know the exact problem you are trying to solve. Therefore, you need to explain the problem and make it crystal clear how bad the problem is (and hence, how great your solution is).
A research problem must be stated explicitly. Therefore, you should have a sentence like this:
- “The problem is… “
- “Problematic with this practice is that…”
- “The disadvantage is…”
… and then you must quantify the problem. The problem must be tangible, i.e. something real. In general, a problem could be that people die or suffer. In computer science, a typical problem is rather:
- Low Accuracy / High Errors
- High Costs / Runtime
- Difficult to use (measured in time)
- …
If readers/reviewers do not understand the problem, they will consider your work as insignificant and ignore/reject it.
A research problem must be as specific and quantifiable as possible. Ideally, you can specify the problem in terms of error, cost, time, or life exactly.
Bad: Researchers struggle to find relevant research papers <— what does “struggle” mean?
Soso: Researchers spend a lot of time to search for relevant work, and yet they often miss some relevant work. <– How much is “a lot of time”? Hours? Days? Months?
Good: Researchers spend an average of 30 hours per month searching for relevant work [3], and yet it is estimated that researchers miss 24% of relevant work [8, 12]. <<— a very specific measurable problem.
If you are so specific, you will also be able to specify the benefit of your work much better once it is completed.
Bad: Our recommender system helps researchers to better find relevant work.
Good: Our recommender system saves researchers on average 12 hours per month, and provides them with 14% more relevant work.
The research problem is presented after your background paragraph. For instance:
Typically, researchers calculate a few metrics for each algorithm (e.g. precision p, normalized discounted cumulative gain nDCG, root mean square error RMSE, mean absolute error MAE, coverage c, or serendipity s). For each metric, they present a single number such as p = 0.38, MAE = 1.02, or c = 97%, i.e. the metrics are calculated based on all data available. <– Background
An issue that has not been addressed by the community, is the question of which intervals metrics should be calculated, and how to present them. Currently, metrics express how well an algorithm performed on average over the period of data collection, which may be quite long. For instance, the data in the MovieLens 20m dataset was collected over ten years [15]. This means, when a researcher reports that an algorithm has e.g. an RMSE of 0.82 on the MovieLens dataset, the algorithm had that RMSE on average over ten years. We argue that presenting a single number (i.e the overall average) is problematic as an average provides only a broad and static view of the data. If someone was asked how an algorithm had performed over time – i.e. before, during, and after the data collection period, the best guess, based on a single number, would be that the algorithm had the same effect all the time.
It is not easy to find the right research problem, because a problem can be very high, or very low level. For instance:
- The world is not advancing as good as it could because…
- Researchers work not as effectively as they could because…
- Researchers face the problem of information overload because …
- Every year so many new research articles are published and because …
- The techniques to deal with information overload (i.e. recommender systems) are not yet effective because…
- It remains unknown, which recommendation approaches are most effective because…
- Most research about recommender systems is not reproducible because …
- …
Each of the points is a valid research problem, and you could theoretically pick any of them. Which one eventually to choose depends on your audience and, of course, what you eventually plan to do.
Research Question
A research question derives from the research problem. For instance:
Research Problem: Most research about recommender systems is not reproducible
Research Question: How to improve reproducibility for recommender-systems research?
Important: Try to avoid yes/no questions and answers. Often, the answer is obvious. Better is a question that allwos a more nuanced answer. For instance,
Bad: Could AI be harmfull to mankind? The answer is obvious, it’s ‘yes’.
Better: What are the risks of AI to mankind? Or “To what extend could AI be harmfull for mankind?”
This question give’s you much more room for an answer.
Research Goal / Objective / Hypothesis / Benefits
There is no clear distinction between a research goal and a research objective. Generally, a goal tends to be more vague, visionary, and long-term oriented than a research objective. For instance,
Research Goal: “Our goal is to reduce information overload for scientists
Research Objective: Our research objective is to develop a recommender system that filters new research articles more effectively than the state-of-the-art.
Or something like
Our goal is to identify how performance assessments of recommendation algorithms differ when time-series are used instead of single-numbers.
A hypothesis is similar and just a different way of expressing. For instance
We hypothesize that, instead of a single number, recommender-systems research would benefit from presentingtime series metrics, i.e. each metric should be calculated for a certain interval of the data collection period, e.g. for every day, week, or month. This will allow to gain more information about an algorithm’s effectiveness over time, identify trends, […]
It is important to note the difference between a goal and a task or methodology. A goal would be to e.g. generate new knowledge or reduce a problem. The following are not goals:
Wrong: Our ‘goal’ is to evaluate Algorithm A and B
Wrong: Our goal is to conduct a survey
Conducting a survey or evaluation is not a research goal. It is a means to achieve your goal, which might be as follows:
Our goal is to identify which of the two algorithms A and B is more effective (and to achieve this goal, we do an evaluation).
Our goal is to identify, how satisfied users are with system ABC (and to achieve this, we conduct a survey)
Similarly,
Wrong: Our goal is to improve recommender systems with machine learning
Using machine learning is not a goal in itself. Your goal may be to improve recommender systems, and using machine learning is the means to achieve it.
Research Tasks
In a normal paper, you do not need to state explicitly the research tasks. Only if you are pursuing a really big project (such as a PhD) you might want to break down your research objective into some tasks and describe them in a separate section.
Contribution
It is crucial that you explicitly state the contribution(s) that you made and the resulting benefit, ideally in a quantified way. You can do this in the introduction, as a separate section, and/or in the conclusion or summary.
The best contributions are:
- Make humans live longer
- Make humans happier
- Save money or time (or increase profit)
In computer science, good contributions are also
- A new algorithm, process or software that is cheaper/faster/better than the state-of-the-art
- A new dataset, method or tool that enables others (e.g. other researchers) do to better work
- Best-practice guidelines (based on actual evidence, not gut feeling)
- New knowledge
Direct benefits that result from your contribution maybe
- Faster training of machine learning algorithms
- Higher effectiveness of algorithms
- Lower energy consumption of servers
- More effective and efficient work of users
- …
Ideally, you can quantify your contribution. For instance:
Our contribution is a novel recommendation algorithm that increases the effectiveness of literature recommendations by 16% over the state of the art, and hence helps to cope better with information overload.
Our contribution is the release of a public dataset, which is the first dataset in the domain of research paper recommender systems. It enables researchers to conduct more realistic research about literature recommender systems.
Don’t confuse a contribution and a task. For instance “We conducted an extensive study with 300,000 users” is no contribution. The evaluation is only the evidence that e.g. your novel algorithm is better than the state-of-the-art (but the contribution is your algorithm). Similarly, simply proposing a novel algorithm is typically not a contribution. Only proposing an algorithm that is x% better than the state-of-the-art is a contribution.
Also, if you are the first to do something, then say so explicitly.
“To the best of our knowledge, we are first to do/use/show …”
If you develop a novel algorithm, then the novel algorithm itself is not a contribution. It is only a contribution in one of the following cases
We introduce a novel algorithm that is 12% faster than the state of the art
We introduce a novel algorithm that is the first algorithm to solve problem x
Background
For a dissertation, it may be necessary to provide additional background information. This background section may contain text-book style information about the broader topic. For instance, an explanation of what machine learning is, how neural networks work, how standard evaluation metrics are calculated, etc. When deciding what information to put in the background section, ask yourself:
- Does an expert in your field know these things already?
- Is similar information already available on Wikipedia or in a textbook?
If yes, then the information should be in the background section. Also, don’t confuse this separate background section with the brief background section in the introduction. The background section in the introduction should be very brief. The separate background section may be long. However, do not spend too much time with this section, as you usually do not get credit for it. Instead, rather point readers to available work (e.g. textbooks).
Related Work
When writing a related-work section, keep the following guidelines in mind.
Only provide information relevant to the research problem
The related work section summarizes what others have done to accomplish the same research objective that you are trying to accomplish. It is not a text-book style introduction to your research topic! For instance, if you develop a novel algorithm for a recommender system in digital libraries, then the related work section should cover other novel algorithms for recommender systems in digital libraries. This means you should describe what other researchers’ attempts were to solve your research problem. Explain why their attempts were not yet successful and what must be done better. The related work section should not explain what recommender systems and digital libraries are and how they work! Such information is not necessary because your audience should know all this already. If you feel such information is necessary, place it in the appendix or a separate background section.
Create New Quantifiable (Meta) Information
A good literature survey, i.e. related work section, a) demonstrates your thorough understanding of the topic and b) provides new knowledge. It does not only summarizes paper by paper. Instead, you critically analyze existing work and provide novel meta information.
Bad
Giles et al. (1999) use collaborative filtering for their recommender system, and use citations as implicit ratings. Beel et al. (2013) use content-based filtering for their recommender system, and use the terms from the documents’ titles. Jon & Doe (2008) also use content-based filtering and use the terms from the documents abstracts. <– In this example, one paper after the other is described. No critical thinking is demonstrated and no new information is provided.
Good
Only in the early times of recommender systems, i.e. in the 1990’s, some authors used collaborative filtering based on citations (e.g. Giles et al. 1999; …). Nowdays, 53% of the reviewed recommender systems use content-based filtering (e.g. Beel et al. 2013; Jon & Doe, 2001) and extract the terms either from the title (Beel et al., 2013) or abstract (Jon & Doe, 2008). However, the results of many studies need to be looked at with care. 72% of the studies were conducted with less than 15 users, and did not provide statistically significant results. <– To write a survey like this, you need to look at each paper and what they exactly did, and then calculate your own statistics. Such a survey provides real additional value.
Have a look at one of our literature surveys for a good example of how to summarize and analyse related work.
Be critical (but fair)
Explain what the shortcomings of the current works are, without letting someone else look stupid. Avoid judgmental words like “bad”, “poor”, “wrong”.
Bad example:
John Doe (2005) conducted a poor user study with only 15 participants. Hence, the results are meaningless.
Good example:
John Doe (2005) conducted a
pooruser study withonly15 participants.Hence, the results are meaningless.While the results are interesting, they are statistically not significant.
Searching For Related Work
Follow the “onion” principle. This means you search first for work that is as closely related to your goal as possible. For instance, when you want to develop a content-based filtering recommender system for digital libraries, then you search for literature about content-based filtering recommender systems for digital libraries. If you do not find (enough) related work then you broaden your search. For instance, you look into “collaborative-filtering based recommender systems for digital libraries”. If you don’t find a lot of work on that, then you search e.g. separately for “recommender systems” and “digital libraries”, or disciplines such as “content-based filtering for recommender systems in academic search engines”.
Methodology
Describe how you will achieve the research objective. Describe the study design, metrics, datasets, libraries being used etc.
Results
The results section should present the results as objectively as possible. Any subjective interpretation should come later in the discussion section (unless you merge the results and discussion sections, which is possible).
Try to visualise your results in an interesting way. This means, don’t show 20 bar charts all showing the same thing. Explore other ways of presenting, e.g. box plots, heat maps and think carefully how you can present as much information in a single chart as possible without having too much information.
Discussion/Interpretation
In this section, you interpret and discuss your results. For instance “given the precision, algorithm A seems to be more effective than B. However, …”.
For smaller projects (e.g. a research paper), you can combine the discussion and results sections.
Conclusion
Here you answer the “so what?”. What do your results really mean? What are your conclusions? Have you achieved your research goal? For instance, “We propose that, given our findings, recommender systems should use algorithm A instead of B”. Again, for rather short manuscripts (research papers), you may merge results, discussion and conclusion.
Summary
In most documents (6+ pages) you should have a summary. The summary should summarize the most important information from each previous section.
Future Work and Limitations
Describe what the limitations of your research are (e.g. “we only used documents from the medical domain, hence our conclusions should not be generalized to other domains”), and what else you might want to do (e.g. “As next steps, we plan to repeat the research with documents from the social sciences. In addition, we want to extend algorithm A with X to see if this further increases precisions”). This section is important. You can demonstrate critical thinking and self-reflection.
References
Reference Styles
There are two main options for referencing papers in computer science and combinations of them. First, you can use brackets, round or quare (see image below “1”); second, you can use the author names and publication years (see image below “2” and “3”). You may also mix the two styles (see image below “4”). What you should not do is use numeric references like [12] and use them as if they were a person, e.g. you should not write “[12] showed that algorithm A outperforms B”.

Appropriate Amount of References
Short papers and posters typically have between 4 and 8 references
Conference articles typically have between 5 and 15 references.
Journal articles typically have between 15 and 50 references.
Bachelor Theses typically have 10-30 references.
Master theses typically have 30-60 references
PhD theses typically have 100+ references.
Manage References
To create references, use reference management software like Zotero, Mendeley, Endnote, or Docear and their add-ons e.g. for MS Word. Do not manually create reference lists.
General Writing Advice
Focus on your audience (not yourself)
When writing a paper, many people focus on themselves and what they know and like. However, you are not writing for yourself. You are 1. writing for the reviewers of your manuscript and 2. for other researchers in your field. More precisely, you want to convince these people that you worked on an important problem, and found a good solution. Therefore, as a first step, think about who your reviewers and readers might be, what they might know already, and what they are interested in reading.
For instance, imagine you want to submit a manuscript about a recommender system that you developed for digital libraries. For yourself, the best thing about Mr. DLib may be that you can collect so much data with it. If you submit the paper to a conference about open data, this focus might be fine. However, if you submit the paper to a conference on digital libraries, you might want to emphasize how Mr. DLib can help digital libraries attract more users. If you submit to a recommender-systems conference, you may want to focus on how technologically sophisticated the recommendation algorithms are.
Another example, not related to academic writing, but writing in general: I received this email from a postdoctoral researcher who wanted to work in my group. The email concludes with the sentence “I am certain that with your guidance my research capabilities will be highly improved”.
I am sure that this email was an honest email. The researcher’s motivation for the email truly was that he wanted to progress his career and gain new knowledge. However, if I am seeking to hire a postdoc, who will earn around 60.000€ p.a., I am not selecting the candidates based on how much my guidance will improve their career. I am selecting candidates based on how much their skills will benefit my research group, i.e. how much they actually will publish, how much they can help my Ph.D. students to progress their careers, how much teaching they will do, and how much research grants they will acquire.
As such, a much stronger ending would have been:
I am certain that with my knowledge and expertise, I would be a valuable addition to your lab, and I would greatly contribute to the success of your lab.
Minimize others’ reading and thinking effort (and not your writing effort)
Do not let the reader speculate or guess about anything, especially not about your conclusions. If you do, there will be readers who do not understand or misunderstand you.
This means, first, you need to explain exactly what e.g. figures show:
Bad: Figure 3 shows that recommendation approach A outperforms approach B.
Good: Figure 3 shows that recommendation approach A achieved a CTR of 3.91% and hence outperforms approach B with a CTR of 3.15%.
Second, you must explain the “so what?”
Bad: Recommendation approach A achieved a CTR of 3.91% and hence outperforms approach B with a CTR of 3.15%.
Good: Recommendation approach A achieved a CTR of 3.91% and hence outperforms approach B with a CTR of 3.15%. This means, our novel recommendation approach (algorithm A) outperforms the state-of-the-art (algorithm B) by 26%.
Parallel Structure
To ease the reading, you should use a “parallel structure”. This means, within a sentence (and paragraph) you follow the same structure.
Example 1: Do not mix forms
Not Parallel: Mary likes hiking, swimming, and to ride a bicycle.
Parallel: Mary likes hiking, swimming, and riding a bicycle.
Example 2: Clauses
Not Parallel: The coach told the players that they should get a lot of sleep, that they should not eat too much, and to do some warm-up exercises before the game.
Parallel: The coach told the players that they should get a lot of sleep, that they should not eat too much, and that they should do some warm-up exercises before the game.
For more details, read here https://owl.english.purdue.edu/owl/resource/623/01/
Avoid brackets
In academic writing there is a simple rule: If something is important, don’t put it in brackets. If something is not important, don’t mention it in the paper.
Use Active Voice / Avoid Passive Voice
Make it crystal clear who did or said something: Always use active voice, never passive voice.
Bad: It was shown that…
Good: We showed that… (or “Author ABC showed that…”)
This is particularly important for things that you did. If you spend a lot of time tuning hyperparameters, don’t write “the hyperparameters were tuned”. Instead, write, “We/I tuned the hyperparameters”. If you use passive voice, the reviewer must guess who did the work, and if you are unlucky, they will guess that it was some other person who did the work.
Write actively
Bad: In this paper, we introduce a software that we developed, named SciPlore Xtract. The software supports developers in extracting titles from PFD files.
Good: We introduce SciPlore Xtract, which extracts titles from PDF files.
A good paragraph
One paragraph = One topic
Do not write about different topics in one paragraph. Instead, have one paragraph per topic.
Bad:
Citation-proximity analysis suffers from the same problems as other citation-based approaches for calculating document-relatedness. This problem relates to the necessity that documents must be cited before document relatedness can be calculated. However, the majority of research papers are not cited at all [3]. In this paper, we propose a novel citation approach to calculate document similarity. This approach does not suffer from the aforementioned problems…
Good:
Citation-proximity analysis suffers from the same problems as other citation-based approaches for calculating document-relatedness. This problem relates to the necessity that documents must be cited before document relatedness can be calculated. However, the majority of research papers are not cited at all [3].
In this paper, we propose a novel citation approach to calculate document similarity. This approach does not suffer from the aforementioned problems…
First Sentence: Mention the topic
The first sentence of each paragraph must mention the main topic the paragraph is about. This way, readers can decide if they want to read the paragraph or skip it and continue with the next one. In addition, mentioning the main topic in the first sentence, allows readers to read only the first sentence of each paragraph and get a good idea what the manuscript is about.
SEXI scheme (State; EXplain; Illustrate/Examples)
The SEXI scheme is typically used for debates to convince the audience of something. The scheme does a very good job for writing, too, because eventually, you need to convince the reader and reviewers that your results are correct and important. The concept of SEXI is as follows.
- State: State your hypothesis/demand clearly (“We must lower income tax!”)
- EXplain: Explain the mechanism, i.e. why you believe in the hypothesis: “With a lower income tax rate, people will have more money to spend, hence buy more products, hence businesses will make more revenue, hire more people and eventually create a higher absolute tax income for the state”. ← you don’t have to agree with this, it’s just for illustration ;-).
- Illustrate: Provide an example and evidence: “Just imagine, what you would do if you could keep 10% more of your salary? Wouldn’t you be more likely to buy a new car? Or go more often to a restaurant?” OR “A recent study in country X showed that after decreasing taxes for individuals, the overall tax revenue increased [4]”)
When writing an academic paper, you need to be more formal, but the general idea is the same.
- You start a paragraph with a statement that clarifies what this paragraph will be about. For instance,
“Citation-proximity analysis suffers from the same problems as other citation-based approaches for calculating document relatedness“. ← This is your opening statement. However, it is just a claim. People may or may not believe it. - Once you made your statement, you need to explain the statement, in case someone did not understand what you mean. And yes, that means that the remainder of the paragraph is only relevant for people who do not understand or agree with your initial statement. All other readers can just skip to the next paragraph. For instance,
“Citation-proximity analysis suffers from the same problems as other citation-based approaches for calculating document relatedness. This problem relates to the necessity that documents must be cited before document-relatedness can be calculated. However, the majority of research papers is not cited at all [3]. In addition, it usually takes a year or longer before a paper receives its first citation [4]. This means citation-based document relatedness can only be calculated for a few documents in a corpus, and typically only for documents being published some time ago“. ← Someone being familiar with citation analysis, will know all this already. However, some other readers might not. - For those who are still not convinced, you provide an example and more evidence:
“Citation-proximity analysis suffers from the same problems as other citation-based approaches for calculating document relatedness. This problem relates to the necessity that documents must be cited before document-relatedness can be calculated. However, the majority of research papers is not cited at all [3]. In addition, it usually takes a year or longer before a paper receives its first citation [4]. This means citation-based document relatedness can only be calculated for a few documents in a corpus, and typically only for documents being published some time ago.For instance, in our Mr. DLib recommender system, only 12% of the documents are co-cited at least once, and only 3.8% of documents are co-cited more than five times [5]. Among the recent documents published in the past two years, only 0.4% of documents are co-cited more than five times. This means Mr. DLib can use citation-based recommendation approaches only for a small fraction of its documents.” ← If a reader still hasn’t understood by now that citation-proximity analysis has some disadvantages when it comes to calculating document relatedness… well, then there is no hope for that person.
You should always (!) keep this in mind, whatever you write. Especially providing examples is super important. An example can also be a screenshot of a GUI or some other illustration. You must be aware that if a reader does not get what you are saying, the reader most likely will not like your work and lose interest.
Balanced length
In a well-written document, each paragraph has around the same length and the longest paragraph might be maybe twice as long as the shortest. If not, it is very likely that the document is not well written and hence difficult to understand. Just make a little experiment when you read your next papers. After reading a paper, decide if you found the paper easy to understand or not. Then zoom out and have a look at how balanced the paragraphs are. I am sure, you will find a very high correlation between “ease of reading” and “balance of paragraph length. But, of course, your own paper is not becoming better by just merging two short paragraphs into one normal-length paragraph. Each paragraph must still follow the SEXI rule, and each paragraph should only be about one SEXI statement.
- Good

- Bad

Short sentences
Make your sentences short. Especially, if you are not a native English speaker!
In the 2-column ACM format, 1.5 or 2 lines should be the standard. Never more than 3 lines!
Avoid brackets
In the 1-column ACM or Springer format, 1 or 1.5 lines should be the standard. Never more than 2.5 lines
In academic writing there is a simple rule: If something is important, don’t put it in brackets. If something is not important, don’t put it in the paper.
Be consistent in your terminology
If you use a certain term (e.g. “item”) then don’t use a different term for the same thing in the next sentence (e.g. “resource”). Look at this example:
Digital libraries provide millions of resources such as books and academic articles. To find such relevant items, the libraries often offer a keyword search. An alternative to discover relevant objects are recommender systems.
The sentence above is difficult to understand because a reader needs to think each time “hm… is an item the same as a resource and is that the same as an object? Much easier to understand is this:
Digital libraries provide millions of resources such as books and academic articles. To find such relevant resources, the libraries often offer a keyword search. An alternative to discover relevant resources are recommender systems.
Another example
“Position bias” describes the tendency of users to interact with items on top of a list with higher probability than with items at a lower rank,
Using once “top of a list” and once “lower rank” is slightly irritating. It would be better to write “items on top of a list […] items at the bottom of a list” or “items at a higher rank […] items at a lower rank”.
(Relative) Numbers, numbers, and numbers
Whenever possible, provide precise numbers, ideally percentages.
Bad: “Many of the reviewed recommender systems apply content-based filtering”
Better: “23 of the reviewed recommender systems apply content-based filtering”
Good: “68% of the reviewed recommender systems apply content-based filtering” Best: “68% (23) of the reviewed recommender systems apply content-based filtering”
Words to Avoid
“many”, “several”, “a lot”, “some”, “numerous”, “much better/worse” …
Avoid vague terms like “much”, “many”, “a lot”, “several”, and “some”. Instead, provide specific numbers and let your reader do the judging. For instance, when you write, “Algorithm A was much more effective than algorithm B”, one reader may think “, ok, algorithm A probably was around 10% more effective than algorithm B”. Another may think that algorithm A was 50% more effective than algorithm B. Hence, it’s better to write, “Algorithm X was 31% more effective than Algorithm Y with an accuracy of 0.46 vs. 0.60 “. The reader himself can then decide if this is “somewhat better”, “a lot better”, or “fucking mindblowing”.
Similarly, if you write, “We evaluated our algorithm with several datasets”, some readers may think of 5 datasets, some may think of 10, and others may think of 50. So, instead of saying “several”, just write the exact number immediately and prevent the reader from making guesses.
“however”
Sometimes, using “however” makes sense. However, in most situations, you can delete it and the sentence’s meaning remains the same. However, if you use “however”, ensure that the sentence containing “however” is a contradiction to the previous sentence. For instance:
Apples are usually green.
However, they taste good. ← However makes no sense here, unless you believe that green things usually taste bad.
Apples are usually green. However, there are also red ones.
Never start a new paragraph with ‘however’!
Never, always, impossible…
As a scientist, your statements must be 100% correct. You must not say something that is “almost” correct. And as a scientist, you should be aware that the world is changing, and the perception of truth may be changing. Hence, avoid absolute terms like “never”, “always”, and “impossible” because they are rarely true. If you say something is always (or never) possible, someone must only find one counter-example to prove you wrong. If you say, “There is no work on topic x”, or “It is impossible to do XYZ”, then someone must only find one crappy blog post on topic x or spend one billion Euros to do XYZ to prove you wrong. If you write, “To the best of our knowledge, there is no work on topic x” or “We did not find any work on topic x” (and then explain where and how you searched), you are making a correct statement.
And even if something is considered “impossible” today, it may not be impossible tomorrow. Think about what society considered to be true about women 100 years ago and what society thought would be impossible for women to do.
“Obviously”, “clearly”, “evident”, “of course”, …
Never use the word “obvious”: If something is obvious, then, obviously, you don’t need to say it. If you feel you need to say it, then it’s not obvious.
Also words like “evident” and “of course” are dangerous and typically superfluous. They are particularly dangerous if the reader disagrees with you. If you write “The data shows that algorithm X performed better than Z”, but the reader disagrees for some reason (because the results have low statistical significance, because whatever) then the reader’s disagreement will be even stronger when you write “The data shows clearly…”.
… use …
Avoid the term “use” or “using”, especially in the title. Something like “… using machine learning…” sounds as if you just took some machine learning algorithm, applied it to your data, and waited to see what came out. Even if that’s what you did, you shouldn’t make it so obvious. Especially your title should create the impression that you created something new. For instance:
Bad: Doing X using Deep Learning
Better: A Convolutional Neural Network Architecture for X
But also in the normal text, avoid the term “use”. Almost always you can just delete it entirely.
For instance
Bad: We used an 80/20 split for the dataset to train and evaluate the model.
Better: We split the dataset 80/20 for train and validation.
Believe
You may believe in god, and little girls may believe in fairy tales or Santa Claus. But as a researcher you hypothesize, assume, or, if it has to be, you make an educated guess. But you don’t believe.
Fair / Unfair
Don’t use the term “(un)fair”, unless absolutely necessary. If you use it, be 100% sure you have an argument that everyone agrees with.
Abstract terms like “object”, “item”, “entity”, “resource”, “class”…
Some nouns describe very vague concepts and every reader may have their own understanding of them.
For instance, computational “resources” may mean RAM, CPU, GPU, Storage (HDD), Storage (HDD)…
Or, when you write…
“Digital libraries provide many resources“.
… different people will have a different understanding of “resources”. A researcher in recommender systems for digital libraries may think of digital books and research articles when reading the term “resources”. The IT manager of a library may think about desks and computers when reading “resources”. The HR manager of a digital library may think of employees.
Therefore, ideally, avoid such vague terms. If you need to use it, provide examples of what you mean:
“Digital libraries provide many resources such as books and research articles
or
“Digital libraries provide many resources such as desk space, computers, and offices to their students.
Words to be Careful With
Reference-terms like “this” or “they”
When you reference a previous object with “this” or “they” or “he”, be 100% sure that the reader understands whom you are referring to. For instance:
Digital libraries provide millions of books. They are …
In this example, it is not immediately clear what “They” is referring to – the libraries or the books? In this example it would be much easier to read if you wrote:
Digital libraries provide millions of books. These books are …
or
Digital libraries provide millions of books. The libraries are …”
Sometimes, you can avoid such situations by not writing twice in the plural (or singular) but once in singular and once in the plural. For instance:
A digital library typically provides millions of books. They are… [clearly refering to the books]
A digital library typically provide millions of books. It is… [clearly refering to a library]
Most importantly, if you use a term like “this”, then you must have previously mentioned something that “this” refers to. For instance, read the following example
[…] The A/B engine records all details about the algorithms, as well as additional information such as when a request was received, when the response was returned, and if a recommendation was clicked. All this information is contained in the dataset. For a more detailed description of Mr. DLib’s architecture and algorithms, please refer to Beel, Aizawa, et al. [2017], Beel and Dinesh [2017a; 2017b], Beel, Dinesh, et al. [2017], Beierle et al. [2017], Feyer et al. [2017] and Siebert et al. [2017]. 3 RELATED WORK This has been downloaded from Github [Beel et al., 2017]. […]
In the above text, it remains unclear what “This” refers to. In addition, a new section (e.g. Related Work) should never ever start with “This”, even if you have mentioned some object in the previous section. You must assume that a reader just starts reading the current section without knowing what has been mentioned in the previous one.
Conclusions (“Therefore”, “Because”)
If you have a chain of arguments, then double and triple check that the arguments are plausible and build upon each other.
Hyphens and Compound Adjectives / Nouns
Use hyphens to ease the reading, and clarify the meaning of words. For instance, when you write “English language learner” (no hyphens), a reader will not know if you are talking about a person who is English and learns another language (English Language-Learner), or if you are referring to a person who learns English (“English-Language Learner). The meaning only becomes clear if you use hyphens.
Consequently, I recommend writing “recommender systems” but “recommender-systems community”, “recommender-systems datasets”….
Most people in the recommender-systems community don’t agree with this way of writing, and write “recommender systems datasets”, “recommender systems community”, etc. but I believe that is bad style.
More details on hyphenation here: https://www.grammarbook.com/punctuation/hyphens.asp
Multiple “example word” such as “such as”, “etc.”, “for instance”
If you provide examples there is no need to write:
Digital libraries such as ACM, SpringerLink, IEEE Xplore, etc. face many challenges .
Each of the words “such as” and “etc” indicates an example and it is sufficient to use one of them
Digital libraries such as ACM, SpringerLink, and IEEE Xplore face many challenges.
OR
The digital libraries ACM, SpringerLink, IEEE Xplore, etc. face many challenges.
“As mentioned previously”
Avoid writing “as mentioned previously”. In short documents, this is never necessary. In long documents, it might be necessary but there are more elegant ways than writing “as mentioned previously”. Also, if you use it, specify where this was mentioned previously.
Bad: As mentioned previously, there is lots of work on recommender system but no work has used graph-based neural networks. Our recommendation approach is first to use a graph-based neural network in the context of recommender system.
Good: Our recommendation approach uses a graph-based neural network. To the best of our knowledge (cf. ´Related Work´, p. 34) we are first to do this.
Abbreviations
Use words that people know and search for e.g. in Google Scholar. This will make it easier for people to read your paper, and to find it via Google Scholar. Consequently, avoid uncommon abbreviations because they will
- make your paper harder to read
- make your manuscript ranked poorly in Google Scholar. For instance, many people will search for “research-paper recommender systems” on Google Scholar, but no one will search for “RPRS” or “RePaReSy”.
However, if you introduce a new concept, for instance, “Citation Proximity Analysis”, then you should use an abbreviation (CPA), because you will use it throughout the paper, and hopefully other people will adopt this new abbreviation in the future.
If you have to use abbreviations, then highlight them in the text, so readers can find them more easily. For instance
For the online evaluation, 57,050 recommendations were delivered to 1,311 users. The primary evaluation metric was click-through rate (CTR). We also calculated mean average precision (MAP) over the recommendation sets. This means, for each set of recommendations (typically ten), the average precision was calculated. For example, when two of ten recommendations were clicked, average precision was 0.2. Subsequently, the mean was calculated over all recommendation sets of a particular algorithm. For the offline evaluation, we removed the paper that was last downloaded from a user’s document collection together with all mind maps and mind map nodes that were created by the user after downloading the paper. An algorithm was randomly assembled to generate ten recommendations and we measured the recommender’s precision, i.e. whether the recommendations contained the removed paper. Performance was measured as precision at rank ten (P@10). The evaluation was based on 5,021 mind maps created by 1,491 users.
Figures (Color, Labels, Data Table, …)
Cross-reference figures in the body text
When you add figures to your paper (and you should add plenty of them), then you must reference them from within the text (see figure below).

Explain figures
Do not just write things like “Figure 4 shows how the algorithms performed” and then proceed to the next result. Instead, always explain exactly what a figure is showing and what can be seen. Be as precise as possible. For instance, look at this figure:
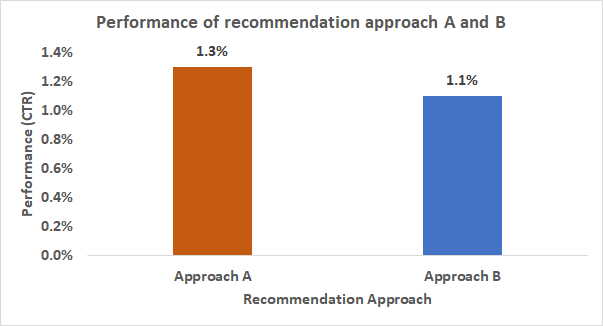
Bad:
“Figure 1 shows the performance of the evaluated recommendation algorithms.” ← This is a vague statement and does not contain any information that is not immedeately visible from the figure itself already (everyone reading the caption of the figure will know that this figure shows the performane of the evaluated recommendation approaches). So, basically, the entrire statement is redundant with the figure caption.
Mediocre:
“Algorithm A outperformed Algorithm B (Figure 1)” ← This is better because it has less words than the above description but provides more information. Imagine, a reader who doesn’t know what CTR is. From the above description the reader wouldn’t know, which of the two approaches performed better.
Good:
“Algorithm A outperformed Algorithm B with a CTR of 1.3% vs. 1.1% (Figure 1)” ← This sentence explains that approach A was better than B and why you think it was better than B. However, it still is too vague because it does not answer what “better than” exactly means. Does it mean ”just a little bit’, or twice as performant? Or 100 times as performant?
Best:
“Algorithm A was 18% more performant than Algorithm B with a CTR of 1.3% vs. 1.1% (Figure 1)” ← The information that A was 18% more performant than B is some highly valuable information that a) cannot easily be seen from the figure and b) quantifies the rather general statement that A was more performant than B.
You may think that it is pretty obvious from the figure that approach A is better than B and why it is better. But imagine more complex charts like this:

In such a chart, it would be much more difficult to understand e.g. which approach was best and why. Hence, you need to explain it (even for simple figures)!
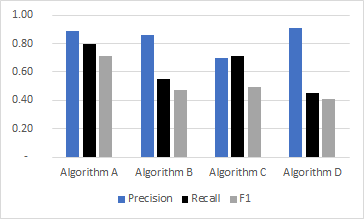
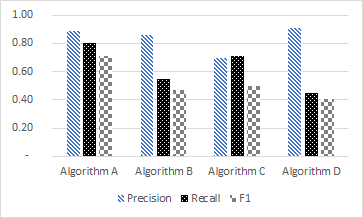
Use different patterns (for B/W printing)
Believe it or not but there are people who are still printing papers and they might print black-and-white. Therefore, when you use colours in your paper, use different patterns for bar charts and lines (e.g. dotted and dashed lines).
- Bad (imagine how this will look when you print it black-and-white):
- Good:
Don’t use green and red (for colour blind people)
Many scientists have difficulties to distinguish between green and red. Hence, avoid using green and red in the same figure.
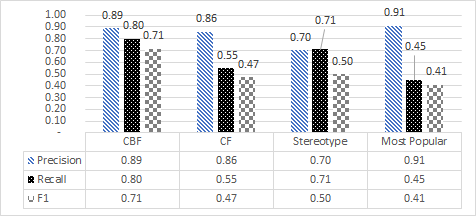
Provide specific numbers
You want others to understand precisely what your results are. To enable them, provide specific numbers either as a label or as a data table.
- Bad (readers have to approximate what e.g. precision for Algorithm A was)
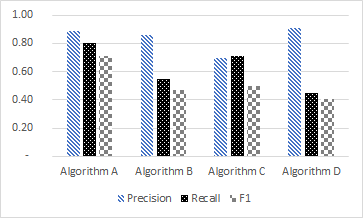
- Good (readers can see the exact numbers; though you don’t need labels and a data table; pick one of the two options)

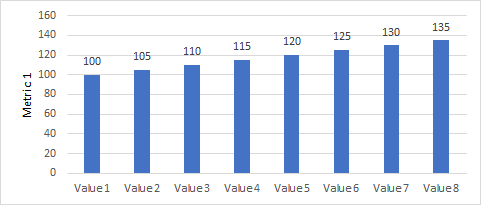
Start the y-axis at 0
Some researchers like to skip the first numbers on the y-axis, which then strengthens the visual effect of their data. Do not do that. It creates the wrong impression that differences are much bigger than they actually are.
- Bad (y-axis starts at 90)
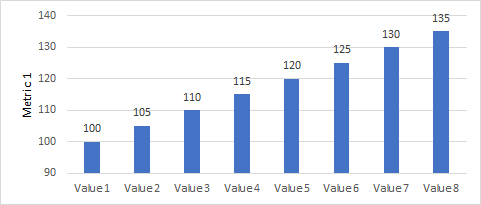
- Good (y-axis stars at 0)
Label the x and y-axis
- Bad (no labels at the axes; the reader doesn’t know what he sees, and must look in the full-text for more details)
- Good (all needed information is contained in the chart)
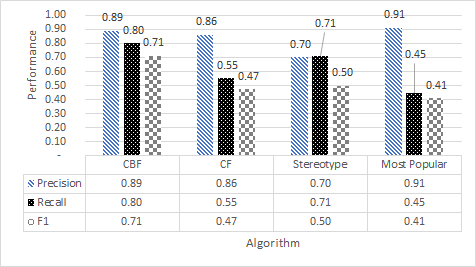
Shrink (but don’t cut) the y-axis as far as possible (don’t waste space)
Usually, space is limited in a research paper. Hence don’t accept the standard size for a figure that e.g. Excel is suggesting. You can easily modify a figure’s height and save lots of space
- Bad
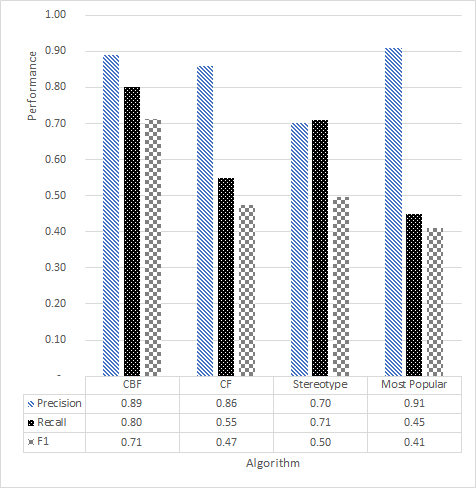
- Good
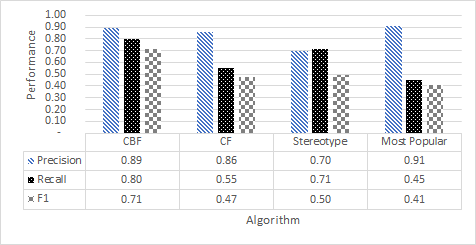
- Also ok (if you need the space)
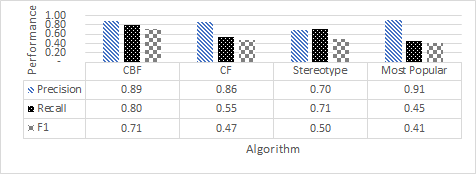
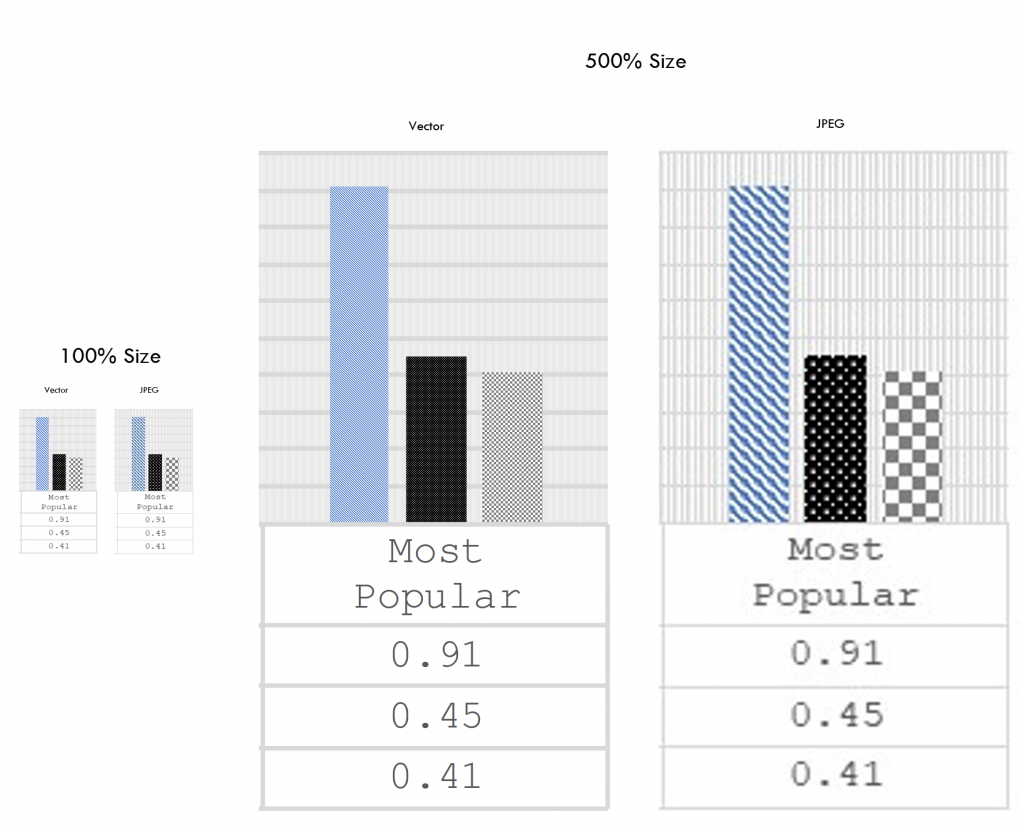
Use Vector graphics instead of bitmaps
If you don’t know why vector graphics are superior to bitmaps, Google it https://www.google.ie/search?q=difference+between+vector+and+bitmap&oq=difference+between+vector. If you don’t know, how to create and insert vector graphics in Microsoft Word, read on.
To add a figure (or table) from MS Excel in MS Word as vector graphic, do the following
- Select the figure in Excel
- Press CTRL+C
- Go to MS Word
- Press CRL+SHIFT+V
- The “Paste Special” dialogue pops out. You select “Picture (Enhanced Metafile”)
Please note, the “Enhanced Metafile” format is always preferred over Bitmap, PNG, JPEG etc. if the source data is in vector format. It’s also to prefer over the “Excel Chart object” or similar.
Here is an example of how vector and bitmap/jpeg differ, especially when you zoom in (click to enlarge the image)
Authorship
Who becomes an author?
Everyone who contributes to a manuscript becomes an author. The most notable contributions are providing an idea, writing the manuscript, providing data, and analysing data. Programming something is not necessarily a contribution (except for demo papers). Persons who have not contributed enough to be an author but still helped to do the work should be mentioned in the acknowledgements.
If you are not sure who should be listed as an author, ask your supervisor. You mustn’t forget anyone. Although you should not “spoil” the list of authors, the worst thing that could happen is that a person is not listed as an author who feels he/she should have been listed. In that case, the person probably has little interest in supporting you in the future.
Author Order
In computer science, the first author is typically the author who authored most of the manuscript and/or the person who contributed most to the paper (ideally, it’s the same person who wrote and did the actual work; then, there won’t be any discussions). A supervisor is typically the last author, at least if the ‘only’ contribution of the supervisor was the supervision and feedback to the paper. If the supervisor wrote the manuscript, he/she would be the first author. Otherwise, authors are ranked by the impact of their contribution. Please note that contribution != invested time.
Responsibilities
The first author is responsible that everything works out fine, i.e. deadlines are kept, other co-authors do what they are supposed to do, the paper is formatted correctly and submitted, and eventually presented at the conference.
Post-Writing
Promoting your Work
https://www.elsevier.com/connect/get-found-optimize-your-research-articles-for-search-engines