
RecSys@NeurIPS2020: 4 Papers about Recommender Systems
NeurIPS 2020 will start in a few days. Given the importance of machine learning for recommender systems, there are many relevant papers. In addition, there are four papers that directly relate to recommender systems:
Sampling-Decomposable Generative Adversarial Recommender
Binbin Jin, Defu Lian, Zheng Liu, Qi Liu, Jianhui Ma, Xing Xie, Enhong Chen
Abstract: Recommendation techniques are important approaches for alleviating information overload. Being often trained on implicit user feedback, many recommenders suffer from the sparsity challenge due to the lack of explicitly negative samples. The GAN-style recommenders (i.e., IRGAN) addresses the challenge by learning a generator and a discriminator adversarially, such that the generator produces increasingly difficult samples for the discriminator to accelerate optimizing the discrimination objective. However, producing samples from the generator is very time-consuming, and our empirical study shows that the discriminator performs poor in top-k item recommendation. To this end, a theoretical analysis is made for the GAN-style algorithms, showing that the generator of limit capacity is diverged from the optimal generator. This may interpret the limitation of discriminator’s performance. Based on these findings, we propose a Sampling-Decomposable Generative Adversarial Recommender (SD-GAR). In the framework, the divergence between some generator and the optimum is compensated by self-normalized importance sampling; the efficiency of sample generation is improved with a sampling-decomposable generator, such that each sample can be generated in O(1) with the Vose-Alias method. Interestingly, due to decomposability of sampling, the generator can be optimized with the closed-form solutions in an alternating manner, being different from policy gradient in the GAN-style algorithms. We extensively evaluate the proposed algorithm with five real-world recommendation datasets. The results show that SD-GAR outperforms IRGAN by 12.4% and the SOTA recommender by 10% on average. Moreover, discriminator training can be 20x faster on the dataset with more than 120K items.
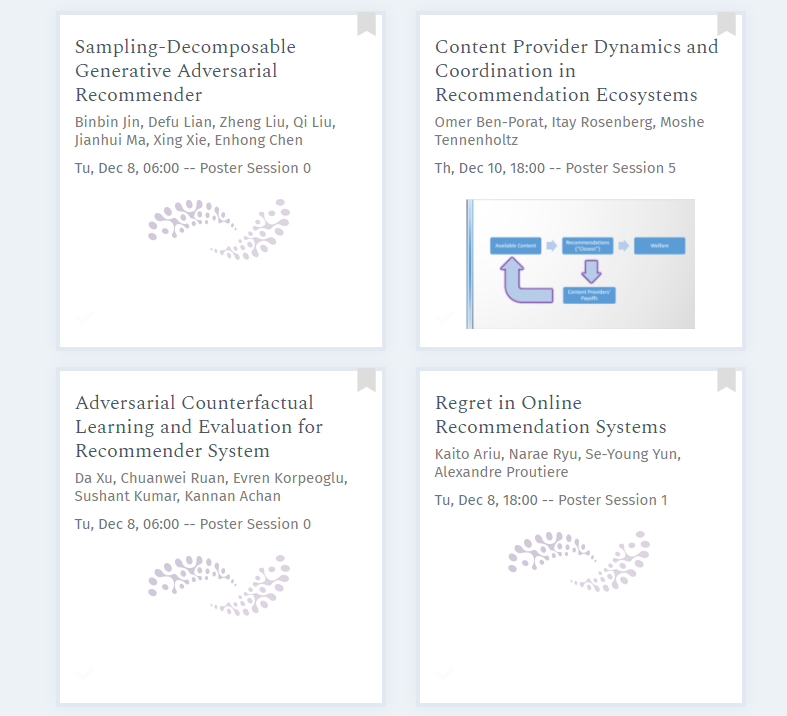
Content Provider Dynamics and Coordination in Recommendation Ecosystems
Omer Ben-Porat, Itay Rosenberg, Moshe Tennenholtz
Abstract: Recommendation Systems like YouTube are vibrant ecosystems with two types of users: Content consumers (those who watch videos) and content providers (those who create videos). While the computational task of recommending relevant content is largely solved, designing a system that guarantees high social welfare for \textit{all} stakeholders is still in its infancy. In this work, we investigate the dynamics of content creation using a game-theoretic lens. Employing a stylized model that was recently suggested by other works, we show that the dynamics will always converge to a pure Nash Equilibrium (PNE), but the convergence rate can be exponential. We complement the analysis by proposing an efficient PNE computation algorithm via a combinatorial optimization problem that is of independent interest.
Adversarial Counterfactual Learning and Evaluation for Recommender System
Da Xu, Chuanwei Ruan, Evren Korpeoglu, Sushant Kumar, Kannan Achan
Abstract: The feedback data of recommender systems are often subject to what was exposed to the users; however, most learning and evaluation methods do not account for the underlying exposure mechanism. We first show in theory that applying supervised learning to detect user preferences may end up with inconsistent results in the absence of exposure information. The counterfactual propensity-weighting approach from causal inference can account for the exposure mechanism; nevertheless, the partial-observation nature of the feedback data can cause identifiability issues. We propose a principled solution by introducing a minimax empirical risk formulation. We show that the relaxation of the dual problem can be converted to an adversarial game between two recommendation models, where the opponent of the candidate model characterizes the underlying exposure mechanism. We provide learning bounds and conduct extensive simulation studies to illustrate and justify the proposed approach over a broad range of recommendation settings, which shed insights on the various benefits of the proposed approach.
Regret in Online Recommendation Systems
Kaito Ariu, Narae Ryu, Se-Young Yun, Alexandre Proutiere
Abstract: This paper proposes a theoretical analysis of recommendation systems in an online setting, where items are sequentially recommended to users over time. In each round, a user, randomly picked from a population of $m$ users, arrives. The decision-maker observes the user and selects an item from a catalogue of $n$ items. Importantly, an item cannot be recommended twice to the same user. The probabilities that a user likes each item are unknown, and the performance of the recommendation algorithm is captured through its regret, considering as a reference an Oracle algorithm aware of these probabilities. We investigate various structural assumptions on these probabilities: we derive for each of them regret lower bounds, and devise algorithms achieving these limits. Interestingly, our analysis reveals the relative weights of the different components of regret: the component due to the constraint of not presenting the same item twice to the same user, that due to learning the chances users like items, and finally that arising when learning the underlying structure.

CfP: 16th ACM International WSDM Conference
Trends in Recommendations Systems – A Netflix Perspective (Upcoming Presentation by Anuj Shah, Senior ML Practitioner at Netflix)

List of 18 Workshops at ACM RecSys 2023 published
About The Author
Joeran Beel
I am the founder of Recommender-Systems.com and head of the Intelligent Systems Group (ISG) at the University of Siegen, Germany https://isg.beel.org. We conduct research in recommender-systems (RecSys), personalization and information retrieval (IR) as well as on automated machine learning (AutoML), meta-learning and algorithm selection. Domains we are particularly interested in include smart places, eHealth, manufacturing (industry 4.0), mobility, visual computing, and digital libraries. We founded or maintain, among others, LensKit-Auto, Darwin & Goliath, Mr. DLib, and Docear, each with thousand of users; we contributed to TensorFlow, JabRef and others; and we developed the first prototypes of automated recommender systems (AutoSurprise and Auto-CaseRec) and Federated Meta Learning (FMLearn Server and Client).