
A New RecSys Blog: MagicMag on Recommender Systems and the Missing ChatGPT Moment
We stumbled on an interesting new blog. It is called MagicMag, and the simple reason to note it is this: our community needs much more work of exactly this kind. Recommender systems are too important to remain trapped between conference papers, company slide decks, and half-public engineering folklore. We need more people who actually work with recommender systems, AI systems, cloud platforms, and product constraints, and who then take the time to write in public. MagicMag does precisely that. The blog presents “AI & Data product insights, from RecSys at Meta to Cloud stuff at AWS” and that description is accurate enough to explain why it matters.
This is also why the author — Maggie Zhuang — matters, even though she likely is not known to many people in the community. On MagicMag, she is introduced as an AI Research PM at Meta, building ranking models for Instagram and Facebook Reels and Feed, with earlier roles at Cash App, Twitter, and AWS. Her LinkedIn profile adds useful detail: it lists a current Meta role centered on questions in RecSys and LLMs, an Intuit role around GenAI platforms and chatbot systems, a Principal PM role for the Cash App data platform, a Staff PM role on ML and data platform work at Twitter, and a Senior PM role in database services at AWS. It also lists a Duke MBA and a master’s degree in computer science from Beijing University of Posts and Telecommunications. That combination is rare. It means the author has both a technical and a business degree, and she worked across ranking, data platforms, cloud infrastructure, and now GenAI systems.
That broader point should be the real theme here. RecSys needs more public technical writing from people who operate at this intersection. The field has no shortage of talent. What it lacks is legible discourse. Too much knowledge remains local to teams, or appears only in heavily filtered forms: polished papers, sanitized blog posts, or product announcements that explain success but not confusion. But confusion is often where the field actually advances. People who have worked on ranking, data, cloud cost, ML platforms, and product deployment are in a good position to identify the real fault lines. When they write clearly, the whole community benefits.
Her first recent post, “The Manifold of Desire” is a good example. Zhuang proposes a compact reading of RecSys history as the gradual addition of dimensions in preference modeling: connection, context, time, and meaning. Matrix factorization maps user–item relations. Deep models bring in contextual features. Sequential architectures make temporal order explicit. The next step, in her account, is a semantic layer that can model intent and content more directly. One may debate the boundaries between these stages, but the framework is technically useful because it treats architecture as a response to representational limits. That is the right level of abstraction.
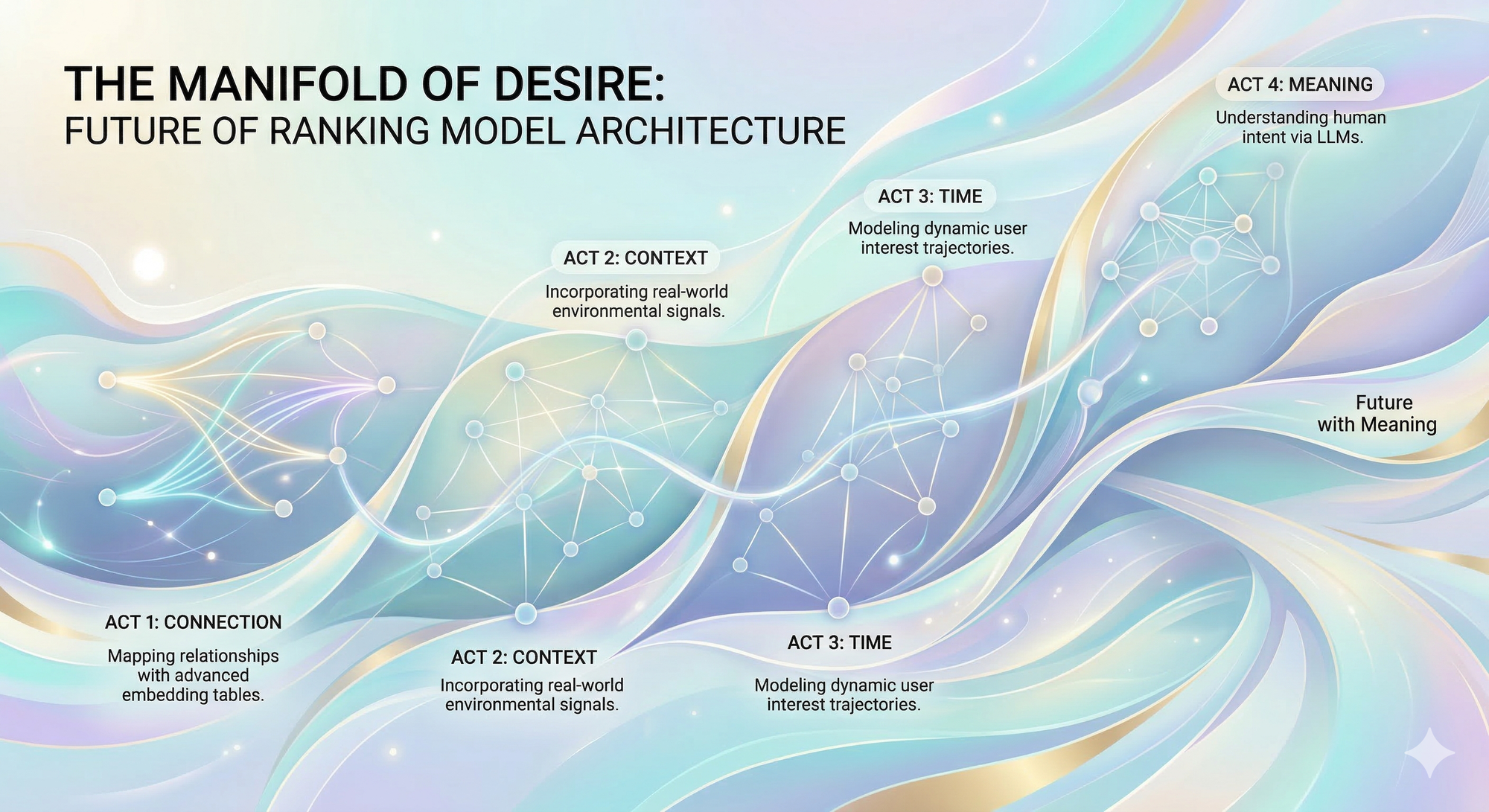
What makes the piece worth reading is not the periodization itself. It is the underlying research instinct. The post asks what exactly our models represent when they predict behavior. Not just scores, but preference traces; not just engagement, but context; not just history, but temporal movement. It is refreshing to see this stated plainly. Much industrial writing on recommendation still talks as if better ranking were mainly a matter of feature volume, training scale, or serving tricks. Those things matter. But they do not remove the representational question. Zhuang puts that question back at the center, and the community needs more of that.
The second post I find noteworthy is “Why RecSys Haven’t Had a ChatGPT Moment“.. Its central claim is that much of today’s recommendation stack still relies too heavily on collaborative filtering over semantically weak item IDs. That, she argues, helps explain cold start, popularity bias, continual retraining, weak transfer, and poor compute efficiency. The comparison with LLMs then becomes straightforward: language models benefit from stable semantic representations, whereas many recommenders still operate on rapidly changing identifiers and interaction patterns. This is a sharp formulation, but it identifies a real research problem.
I agree with the general claim behind the title. RecSys does need an “aha moment” of that kind: a point where the field gains a more convincing semantic foundation and, with it, a new degree of generalization, transfer, and cumulative learning. My hesitation is only about emphasis. The phrase “haven’t had a ChatGPT moment” sounds more absolute than necessary, and some contrasts between LLMs and RecSys are drawn a bit too strongly. Recommendation has always lived under harsher deployment constraints: non-stationary inventories, delayed rewards, online feedback loops, policy constraints, and severe latency budgets. These constraints complicate architecture. Still, this does not weaken the core question. It strengthens it. If RecSys remains central to modern digital systems, then the community should ask more often why its conceptual breakthroughs remain less visible and less cumulative than those in neighboring parts of AI.
This brings us back to MagicMag itself. The value of the blog is not just that it offers two interesting essays. Its value is structural. It is written by someone who has worked across recommendation, cloud infrastructure, data platforms, and now GenAI, and who is willing to connect these domains in public. That is exactly the type of voice the field needs more often. We do not need more generic commentary about “AI transformation.” We need more technically literate practitioners who can explain how representation, architecture, hardware, product requirements, and system economics interact in real RecSys work. MagicMag suggests that this can be done without collapsing into either hype or narrow implementation detail.
So the main takeaway is simple. Yes, the two posts are worth reading. “The Manifold of Desire” offers a concise architectural narrative for the field. “Why RecSys Haven’t Had a ChatGPT Moment” asks a strategic question that the community should take seriously. But beyond these individual texts, the larger point is more important: recommender systems need more public technical writing from people who actually build these systems and who also understand the adjacent layers around them. More such writing would make the field clearer, more self-critical, and probably faster. MagicMag is a good start. The community would profit from many more blogs of this kind.

Green Recommender Systems: A Call for Attention

Interview with Max Harper (Co-Chair of ACM RecSys 2022) on Career Choices, Work-Life Balance, and More

RS_c moves from X/Twitter to LinkedIn as the primary social channel
About The Author
Joeran Beel
I am the founder of Recommender-Systems.com and head of the Intelligent Systems Group (ISG) at the University of Siegen, Germany https://isg.beel.org. We conduct research in recommender-systems (RecSys), personalization and information retrieval (IR) as well as on automated machine learning (AutoML), meta-learning and algorithm selection. Domains we are particularly interested in include smart places, eHealth, manufacturing (industry 4.0), mobility, visual computing, and digital libraries. We founded or maintain, among others, LensKit-Auto, Darwin & Goliath, Mr. DLib, and Docear, each with thousand of users; we contributed to TensorFlow, JabRef and others; and we developed the first prototypes of automated recommender systems (AutoSurprise and Auto-CaseRec) and Federated Meta Learning (FMLearn Server and Client).