
Elliot: a Comprehensive and Rigorous Framework for Reproducible Recommender Systems Evaluation [Guest Post]
In the last decade, Recommendation Systems (RSs) have gained momentum as the pivotal choice for personalized decision-support systems. The recommendation task is essentially a retrieval task where a catalog of items is ranked in a personalized way, and the top-scoring items are presented to the user. Once the RSs’ ability to provide personalized items to clients had been demonstrated, both academia and industry began to devote their attention to them. This collective effort resulted in an impressive number of recommendation algorithms, ranging from memory-based to latent factor-based, as well as deep learning-based methods. At the same time, the RS research community realized that focusing only on the accuracy of results could be harmful and started exploring beyond-accuracy evaluation.
As accuracy was identified to be not sufficient to guarantee user satisfaction, novelty and diversity came into play as new dimensions to be analyzed when comparing algorithms. However, this was only the first step in the direction of a more comprehensive evaluation. Indeed, more recently, the presence of biased and unfair recommendations towards user groups and item categories has been widely investigated. The abundance of possible choices has generated confusion around choosing the correct baselines, conducting the hyperparameter optimization and the experimental evaluation, and reporting the details of the adopted procedure. Consequently, two major concerns have arisen: unreproducible evaluation and unfair comparisons.
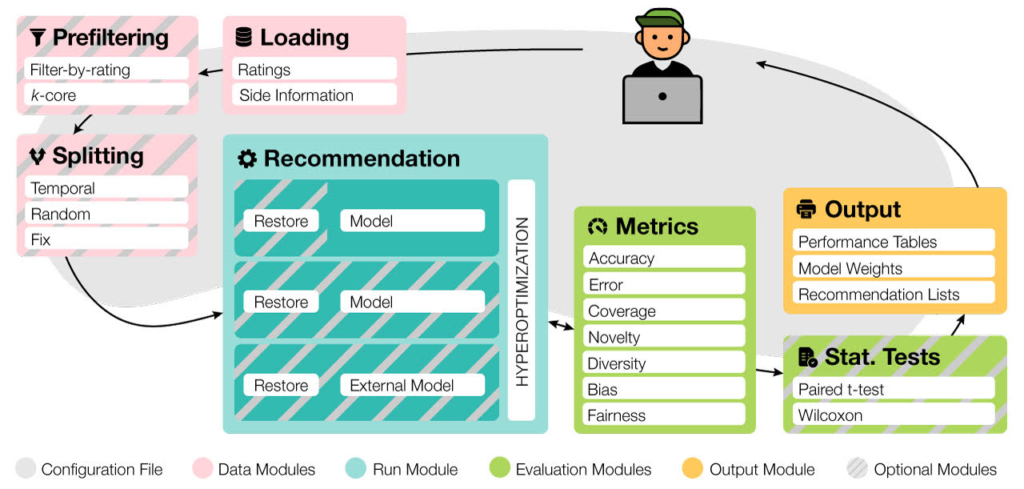
These two motivations inspired us to design Elliot. It is a novel kind of recommendation framework aimed to overcome these obstacles by proposing a fully declarative approach (using a configuration file) to the set-up of an experimental setting. It analyzes the recommendation problem from the researcher’s perspective as it implements the whole experimental pipeline, from dataset loading to results gathering, in a principled way.
Our main idea behind Elliot is to keep an entire experiment reproducible and put the user (in our case, a researcher or RS developer) in control of the framework. According to the recommendation model, Elliot allows, to date, the choice among 27 similarity metrics, 55 recommendation models, the definition of multiple neural architectures, and 51 hyperparameters tuning combined approaches with early-stopping criteria, unleashing the full potential of the HyperOpt library. To enable evaluation for the diverse tasks and domains, Elliot supplies more than 36 metrics (including Accuracy, Error-based, Coverage, Novelty, Diversity, Bias, and Fairness metrics), 13 splitting strategies, 8 prefiltering policies, and 2 t-test strategies. Then, all these functionalities can be used by building a single configuration file (below an example).
In the 0.3.1 Elliot release, we have made available the possibility to evaluate recommendation lists generated with your custom models with Elliot and make them compared with all the models available in the framework. In this way, you can make use of all the functionalities even if your model has been implemented with other programming languages. You need only to pass the dataset and the recommendation lists, and Elliot will evaluate all the metrics.

How to Download
The entire Framework is available at https://github.com/sisinflab/elliot.
A comprehensive and day-by-day updated documentation is available at https://elliot.readthedocs.io/en/latest/.
How to Start
Elliot works with the following operating systems:
- Linux
- Windows 10
- macOS X
To easily start with Elliot run the following commands:
git clone https://github.com//sisinflab/elliot.git && cd elliot
virtualenv -p /usr/bin/python3.6 venv # your python location and version
source venv/bin/activate
pip install --upgrade pip
pip install -e . --verbose
python sample_hello_world.pyNow, let’s have fun with Elliot!
Authors
Elliot is developed by
- Vito Walter Anelli (vitowalter.anelli@poliba.it)
- Alejandro Bellogín (alejandro.bellogin@uam.es)
- Antonio Ferrara (antonio.ferrara@poliba.it)
- Daniele Malitesta (daniele.malitesta@poliba.it)
- Felice Antonio Merra (felice.merra@poliba.it)
- Claudio Pomo* (claudio.pomo@poliba.it)
- Francesco Maria Donini (donini@unitus.it)
- Tommaso Di Noia (tommaso.dinoia@poliba.it)
It is maintained by SisInfLab Group and Information Retrieval Group.

‘Lazy Predict’ Tutorial for AutoML with scikit-learn [Eryk Lewinson]
RS_Datasets: Download, Unpack and Read Recommender Systems Datasets into pandas.DataFrame [Darel13712]

Oracle announces Tribuo, a Java machine-learning library [Adam Pocock @ Oracle]
About The Author
Felice Antonio Merra
I am Felice Antonio Merra a PhD Student working on Security and Adversarial Machine Learning on Recommender Systems. I am earning my Ph.D. in Computer Science and Engineering at Department of Electrical Engineering and Information Technology, Polytechnic University of Bari @PolibaOfficial working with Prof. Tommaso Di Noia. I did a Summer Internship as Applied Scientist at Amazon.com in the Amazon Search and Personalizetion Team.