
Scalable Recommender Systems with NVTabular- A Fast Tabular Data Loading and Transformation Library [Ronay Ak @ Medium]
Ronay Ak et al. from RapidsAI wrote a nice in-depth post on how to use NVIDIA´s NVTabular to develop a recommender system that works with large amounts of data (1.3 TB).
In this blog we will walk you through the NVTabular workflow steps in an example where we use ~1.3TB Criteo dataset shared by CriteoLabs for the predicting ad click-through rate (CTR) Kaggle challenge. We’ll show you how to use NVTabular as a preprocessing library to prepare the Criteo dataset on a single V100 32 GB GPU. The large memory footprint of this dataset presents an excellent opportunity to highlight the advantages of the online fashion in which NVTabular loads and transforms data much larger than what fits into available GPU memory.
https://medium.com/rapids-ai/gpu-recommender-systems-with-nvtabular-eee056c37ea0
Building a content-based music recommender-system [Amol Mavuduru @TowardsDataScience]

LinkedIn introduces “GDMix”, a deep ranking personalization framework
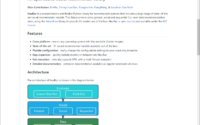
NeuRec: An open source neural recommender library [Bin Wu et al.]
About The Author
Joeran Beel
Founder of Recommender-Systems.com (RS_c) and Professor of Intelligent Systems at the University of Siegen, Germany