
TensorFlow introduces a new ‘end-to-end’ solution for on-device recommendations with TFLite
Ellie Zhou, Tian Lin, Cong Li, Shuangfeng Li, and Sushant Prakash from TensorFlow announced in a blog post that they open-source an end-to-end solution for TFLite on-device recommendation tasks.
TFLite is a TensorFlow-based library for machine-learning on mobile and IoT devices. So far, TFLite had machine-learning models for image classification, object detection, pose estimation, and many tasks more, though not for recommendations. This is about to change.
We are excited to open source an end-to-end solution for TFLite on-device recommendation tasks. We invite developers to build on-device models using our solution that provides personalized, low-latency and high-quality recommendations, while preserving users’ privacy.
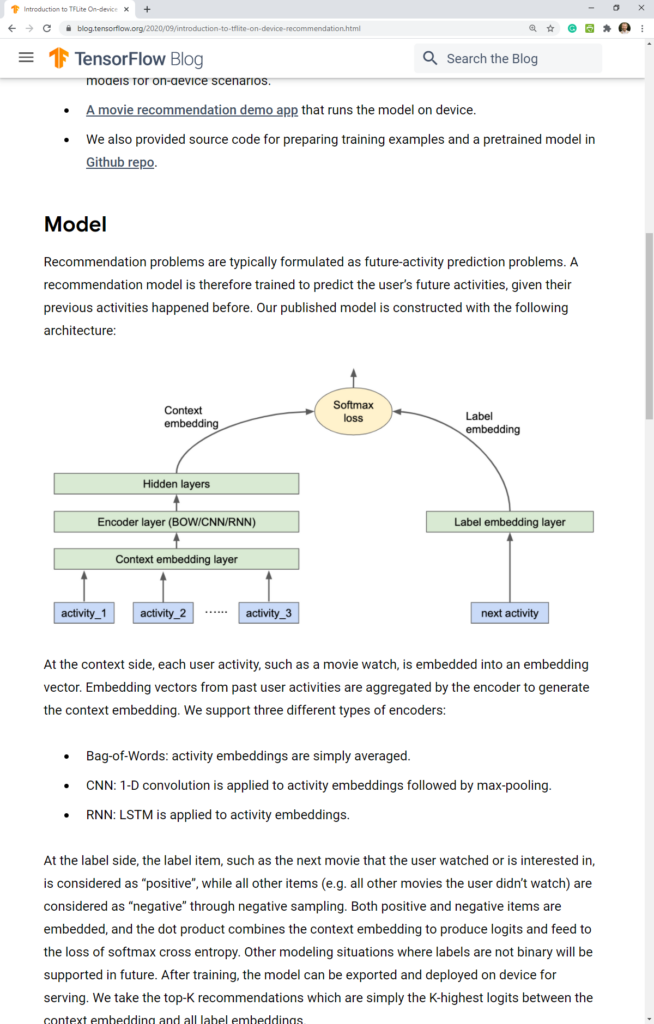
Generating personalized high-quality recommendations is crucial to many real-world applications, such as music, videos, merchandise, apps, news, etc. Currently, a typical recommender system is fully constructed at the server side, including collecting user activity logs, training recommendation models using the collected logs, and serving recommendation models.
While purely server-based recommender systems have been proven to be powerful, we explore and showcase a more lightweight approach to serve an recommendation model by deploying it on device. We demonstrate that such an on-device recommendation solution enjoys low latency inference that is orders of magnitude faster than server-side models. It enables user experiences that cannot be achieved by traditional server-based recommender systems, such as updating rankings and UI responding to every user tap or interaction.
Moreover, on-device model inference respects user privacy without sending user data to a server to do predictions, instead keeping all needed data on the device. It is possible to train the model on public data or via an existing proxy dataset to avoid collecting user data for each new use case, which is demonstrated in our solution. For on-device training, we would refer interested readers to Federated Learning or TFLite model personalization as an alternative.

Zalando publishes its RESTful API and Event Guidelines

Recommender-Systems Version Control: TensorFlow releases ‘Machine Learning Metadata (MLMD)’
RecList: A RecSys software library for behavioral testing
About The Author
Joeran Beel
Founder of Recommender-Systems.com (RS_c) and Professor of Intelligent Systems at the University of Siegen, Germany