
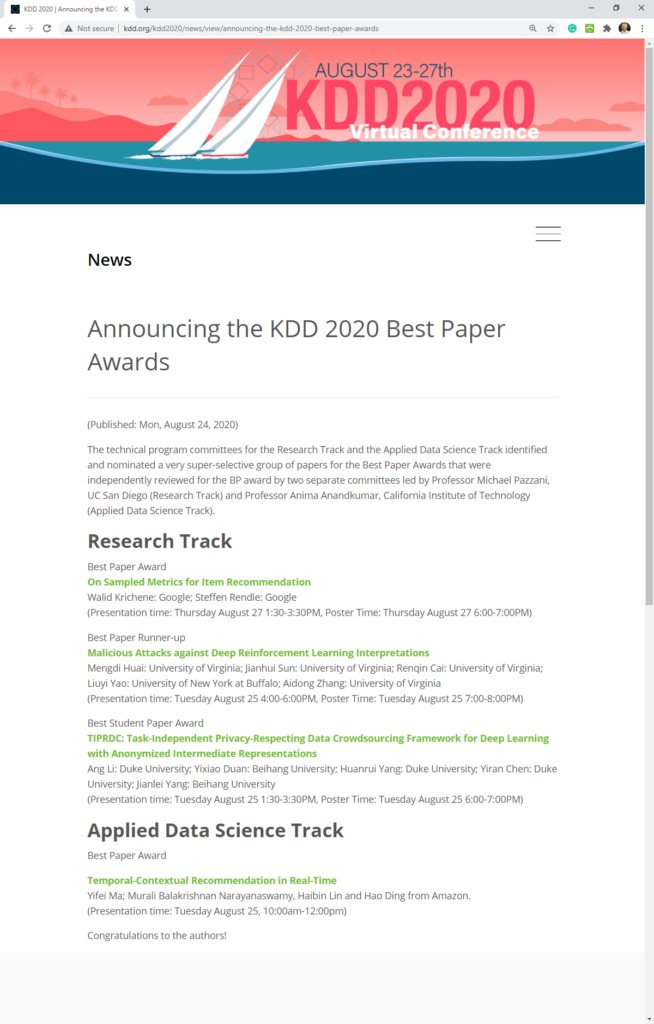
50% of the best-paper awards at KDD 2020 go to recommender-systems papers
September 16, 2020
KDD 2020 has announced its best-paper awards. Out of the 4 awards (3 research track, 1 applied data science track), 2 papers are related to recommender systems.
- On Sampled Metrics for Item Recommendation by Walid Krichene (Google) and Steffen Rendle (Google)
The task of item recommendation requires ranking a large catalogue of items given a context. Item recommendation algorithms are evaluated using ranking metrics that depend on the positions of relevant items. To speed up the computation of metrics, recent work often uses sampled metrics where only a smaller set of random items and the relevant items are ranked. This paper investigates sampled metrics in more detail and shows that they are inconsistent with their exact version, in the sense that they do not persist relative statements, e.g., recommender A is better than B, not even in expectation. Moreover, the smaller the sampling size, the less difference there is between metrics, and for very small sampling size, all metrics collapse to the AUC metric. We show that it is possible to improve the quality of the sampled metrics by applying a correction, obtained by minimizing different criteria such as bias or mean squared error. We conclude with an empirical evaluation of the naive sampled metrics and their corrected variants. To summarize, our work suggests that sampling should be avoided for metric calculation, however if an experimental study needs to sample, the proposed corrections can improve the quality of the estimate. - Temporal-Contextual Recommendation in Real-Time by Yifei Ma, Murali Balakrishnan Narayanaswamy, Haibin Lin and Hao Ding, all from Amazon.
Personalized real-time recommendation has had a profound impact on retail, media, entertainment and other industries. However, developing recommender systems for every use case is costly, time consuming and resource-intensive. To fill this gap, we present a black-box recommender system that can adapt to a diverse set of scenarios without the need for manual tuning. We build on techniques that go beyond simple matrix factorization to incorporate important new sources of information: the temporal order of events [Hidasi et al., 2015], contextual information to bootstrap cold-start users, metadata information about items [Rendle 2012] and the additional information surrounding each event. Additionally, we address two fundamental challenges when putting recommender systems in the real-world: how to efficiently train them with even millions of unique items and how to cope with changing item popularity trends [Wu et al., 2017]. We introduce a compact model, which we call hierarchical recurrent network with meta data (HRNN-meta) to address the real-time and diverse metadata needs; we further provide efficient training techniques via importance sampling that can scale to millions of items with little loss in performance. We report significant improvements on a wide range of real-world datasets and provide intuition into model capabilities with synthetic experiments. Parts of HRNN-meta have been deployed in production at scale for customers to use at Amazon Web Services and serves as the underlying recommender engine for thousands of websites.
About The Author
Joeran Beel
Founder of Recommender-Systems.com (RS_c) and Professor of Intelligent Systems at the University of Siegen, Germany